python
糗事百科 内涵段子
一、糗事百科 内涵段子
糗事百科和内涵段子:哈哈笑中展现的无限幽默
糗事百科和内涵段子是中文互联网上备受关注和喜爱的两个笑话分享平台。无论你是需要一点搞笑放松,还是想尽情开怀大笑,这两个平台都能给你带来无尽的欢乐。不仅如此,糗事百科和内涵段子还成为了许多网友交流互动的热门话题,带来了更多的社交乐趣。
糗事百科:揭开生活的笑点
糗事百科作为中国最大的笑话分享社区,吸引了大量的用户加入其中。这个平台充满了生活的趣味和幽默,让人在笑声中发现糗事的趣味和智慧。
在糗事百科上,人们可以分享自己在日常生活中遇到的搞笑糗事,或者是听到的有趣笑话。这些糗事和笑话往往能够引发人们的共鸣和理解,带来欢乐和轻松。每个人都有自己的糗事和笑话,通过糗事百科的分享,大家可以一起发现生活的乐趣。
糗事百科的内容包括了各个生活领域,无论是工作、学习、娱乐还是家庭,都有人们的糗事或者有趣经历。通过阅读这些故事,人们可以看到生活中的不完美和趣味,同时也能学会以幽默的态度去面对生活中的困境。
此外,糗事百科还提供了评论和点赞系统,用户可以对他人的糗事进行评价和表达自己的观点。这种交互和互动模式让人们更加享受分享和笑声带来的畅快感。人们可以通过评论和点赞与他人互动,分享笑声,交流喜悦。
内涵段子:幽默横行的乐土
内涵段子是另一个备受欢迎的幽默分享平台,它以内涵图片和短篇笑话为主要内容,给人们带来了更多的快乐。
内涵段子的特点之一是其搞笑的图片和漫画,这些图片往往能够以一种简单直观的方式传达幽默和笑点。无论是通过文字表达还是图片插图,内涵段子都能够让人在一瞬间捕捉到笑点,并引发大笑。
此外,内涵段子中的短篇笑话也是一大亮点。这些笑话往往以简洁明快的方式表达,让人忍俊不禁。它们包含着生活的智慧和趣味,往往能够令人意想不到的笑翻。
内涵段子的内容丰富多样,涵盖了各种主题和领域。不论你偏好的是文化、娱乐、科技还是社会,内涵段子都能够满足你的笑点。这个平台吸引了大量的创作者和用户,通过他们的分享和互动,内涵段子成为了一个充满创意和笑声的乐土。
糗事百科和内涵段子的共同特点
糗事百科和内涵段子不仅在内容上有所不同,也有一些共同的特点。它们的共通特点使得这两个平台受到了广大网友的喜爱。
首先,糗事百科和内涵段子都以幽默和搞笑为主题,通过分享笑话和幽默故事给人们带来欢乐和轻松。这种轻松愉快的氛围让许多网友喜欢在闲暇时刻浏览这些平台,寻找一些放松和娱乐的时光。
其次,糗事百科和内涵段子都具有用户互动和社交交流的特点。用户可以在平台上评论、点赞和转发他人的糗事和段子,通过互动和分享来增加交流和社交乐趣。这种互动模式不仅拉近了用户之间的距离,也促进了更多有趣内容的产生。
最后,糗事百科和内涵段子都是一个开放和自由的平台。无论是创作者还是用户,每个人都能够自由表达自己的观点和创作。这种开放性和自由度使得平台上的内容多样性和创造力得以展现。同时,它们也为很多有潜力的创作者提供了一个展示和分享的舞台。
总结
糗事百科和内涵段子以它们独特的幽默和搞笑吸引了众多的用户。这两个平台成为人们放松、分享和交流的乐园。无论你是想寻找笑点,还是享受与他人的互动,糗事百科和内涵段子都能够带给你无穷的欢乐和乐趣。
二、内涵段子和糗事百科
内涵段子和糗事百科-欢迎来到幽默笑话世界
简介
内涵段子和糗事百科是两个非常流行的幽默笑话应用程序。无论是在匆忙的上班途中需要放松一下,还是在休闲时光中享受一些娱乐内容,这两个平台都能带给用户无尽的欢笑,让生活更加有趣。
内涵段子和糗事百科以其独特的幽默风格迅速赢得了广大用户的喜爱。它们提供了大量的笑话、趣闻和搞笑图片,令人捧腹大笑。这些应用程序不仅适合个人使用,也适合与朋友分享。用户可以通过发短信、分享到社交媒体或直接在应用内与其他用户交流,增加了互动和社交的乐趣。
这两个平台的内容十分丰富,从搞笑的故事、冷笑话,到搞怪的图片、视频,应有尽有。用户可以根据自己的喜好选择分类,如爆笑糗事、恶搞内涵、幽默段子等。无论是喜欢笑话的人还是需要一些解压的人,都可以在这里找到适合自己的笑料。
乐趣与益处
笑话是人们生活中必不可少的一部分,它们能够缓解压力,让人快乐起来。内涵段子和糗事百科作为专门提供笑话的平台,不仅为用户带来乐趣,还有一些隐藏的益处。
首先,笑话能够帮助人们放松身心,缓解压力。在忙碌的生活中,合理的放松对身体和心理健康非常重要。当人们在阅读内涵段子和糗事百科的笑话时,他们会忍不住地笑出声,这有助于释放紧张情绪,使人放松愉快。
其次,笑话有助于改善人际关系。当你在朋友间讲一个搞笑的故事或糗事时,不仅能够让大家欢笑,还能够拉近彼此之间的距离,加强友谊。内涵段子和糗事百科提供了大量的笑话素材,让你随时都能成为聚会上的开心果。
此外,笑话还能够激发人们的创造力和幽默感。通过阅读别人创作的笑话,你会受到一些启发,从而培养自己的创造力。而在内涵段子和糗事百科平台上,用户可以自己发布符合规定的笑话内容,通过分享自己的幽默感,不断提升笑料创作的能力。
平台展示
内涵段子和糗事百科都有自己的官方应用程序和网站,用户可以根据自己的喜好选择合适的平台访问。
内涵段子
- 官方应用程序名称:内涵段子
- 应用平台:Android、iOS
- 功能特点:
- 海量笑话资源
- 个性化推荐
- 社交分享和互动
- 创作和发布笑话
- 用户评价:内涵段子平台上的笑话内容丰富多样,贴合用户的口味。用户通过点赞、评论和分享等方式可以与其他用户进行互动,带来更多乐趣。
糗事百科
- 官方网站名称:糗事百科
- 网站地址:
- 功能特点:
- 经典笑话精选
- 段子排行榜
- 用户发布段子
- 段子评论和投票
- 用户评价:糗事百科网站上的笑话常常引人发笑,有些段子经典流传已久。用户可以自由投稿,通过评论和投票表达自己的观点,参与到段子创作和评选中。
三、糗事百科笑话幽默段子
大家好!今天我要和大家分享一些非常有趣的糗事百科笑话幽默段子。笑话是一种幽默的表达方式,它能够带给我们欢乐和放松的心情。无论是与朋友聚会,还是在工作生活中,适时地讲一些笑话都能够增添乐趣。
1. 机智的建筑师
从前有一位聪明的建筑师,他设计了一座桥,但是桥的弯曲造型引起了人们的质疑,于是有人问他:“为什么你设计的桥这么奇怪呢?”
建筑师回答道:“你们不明白,我设计的这座桥能够让行人在上面行走时,既能欣赏风景,又能够休息。因为行人必然会因为桥的曲线而停下来,这样能够让他们稍作休息后再继续前行。”
2. 搞笑的交通情景
一天,小明走在路上,突然发现前面的交通情况非常糟糕,车辆都堵在了一起,一点儿也不流畅。他忍不住对旁边一位行人说:“看看,这就是我们国家的交通状况!”
那个行人笑着回答:“没错,但幸好我们只是旅游,不是交通。”
3. 错误的电话号码
一天,小李打电话给小王,可是接电话的却是一个陌生人。小李问:“对不起,先生,您是小王吗?”
陌生人回答说:“不好意思,我不是小王。”
小李有些疑惑地问:“那您是谁呢?”
陌生人答道:“我是小李。”
4. 笑坏了的牙科医生
一位牙科医生给一名患者看牙,患者咬住了他的手指,他疼得直跳脚,却还是忍住痛苦对患者说:“您咬得好,我已经很久没有这么好笑过了!”
5. 警察与小偷的对话
一名警察走进一家商店,发现一个小偷正在偷窃。他走过去对小偷说:“我是警察,你被逮捕了!”
小偷惊讶地问:“你怎么知道?”
警察淡定地回答:“因为这是警察局。”
6. 搞笑的电梯
小明走进了一座陌生的大厦,他按下了电梯按钮,等了好久电梯也没有到来。他非常着急,就在旁边的墙上看到了一个标志,上面写着:“电梯已停运,请使用楼梯。”
于是,小明愤愤地说:“这个电梯怎么停运了?我都按了十几次按钮了!”
7. 邮票收藏家
一位邮票收藏家去拜访一位朋友,他很自豪地展示着自己的邮票收藏。朋友看了一眼就问:“你怎么只有一张邮票呢?”
邮票收藏家惊讶地回答:“这可不是一张普通的邮票!这是我收藏的唯一的一张罕见邮票,非常珍贵!”
朋友摇摇头,无奈地说:“那你的收藏家名号可就有点勉强了。”
8. 形象化的别称
老师在课堂上问学生:“在生活中,我们经常使用‘玉树临风’来形容一个人。那你们知道‘玉树临风’的反义词是什么吗?”
学生们想了很久,有人提出:“如果‘玉树临风’代表一个英俊潇洒的男子,那反义词就是‘瓜根蒂瓜’了!”
9. 特别的执照
小明去申请驾驶执照,考官问:“你会开车吗?”
小明含糊地答:“大概会吧。”
考官继续问:“那你喜欢开什么车?”
小明毫不犹豫地回答:“都行,只要有车管所发的执照就行!”
10. 出乎意料的赞美
一天,小华对小明说:“你的头发真漂亮!”
小明感到十分惊讶,因为自己是秃顶的。他疑惑地问:“你说的是我的头发吗?”
小华哈哈大笑:“当然了,你的头皮真光滑!”
以上就是我为大家整理的一些糗事百科笑话幽默段子,希望能给大家带来欢乐和轻松的心情。笑话的力量是巨大的,它可以缓解紧张的气氛,让人们放松,同时也展现出人们的智慧和幽默感。笑话不仅仅是娱乐,也是一种生活的调味品,让我们更加享受生活的美好。
如果您也有一些好玩的笑话,不妨分享给身边的朋友,让更多的人感受到快乐。笑一笑,十年少,快乐人生从一颗笑脸开始!
四、Python可以爬取网易云VIP音乐吗?
最近一个朋友和我聊天的时候说想听一首歌,可是要会员,问我要怎么才能下载下来。。因为前几天群里一个朋友刚发了一个python爬取图片的爬虫,于是我打开了他写的代码,仔细研究了一下后,我根据他写的代码,进行了一系列的改造,最终完成了这个python爬取音乐的爬虫~~
python爬虫下载会员音乐
安装python环境
第一步肯定是安装一个python环境啦。。因为网上教程很多,就不多说了,可以自行搜索安装方法的。
其次就是安装IDE啦。推荐:pycharm,如果你想用txt文本写也可以。
开始写代码啦
引入需要的包
import requests
from lxml import etree进入正题了
定义两个变量用来保存url
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="利用requests库向网站发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")接下来就要遍历获取到的url列表,下载服务器上的歌曲了
for data in id_list:
#获取歌曲的链接
href = data.xpath("./@href")[0]
#把链接进行分隔
music_id = href.split("=")[1]
#获取歌曲名称
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
#请求歌曲下载地址
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)那就开始正式下载网易云音乐吧~~~
下面就把完整代码贴出来吧~
import requests
from lxml import etree
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="
#向网址发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")
for data in id_list:
href = data.xpath("./@href")[0]
music_id = href.split("=")[1]
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)
#学习加喂:lbt13732741834此代码仅供学习使用,请勿用于商业用途
学习加喂:lbt13732741834
我很刑 | 用python爬了一万首会员歌曲五、糗事百科跟内涵段子什么关系
糗事百科跟内涵段子什么关系
在中国的互联网世界中,糗事百科和内涵段子无疑是两个备受瞩目的社交娱乐平台。这两个平台带给用户无尽的欢乐和娱乐,但是很多人常常混淆它们之间的关系。那么,糗事百科和内涵段子究竟有什么关系呢?
要理解糗事百科和内涵段子之间的关系,我们首先需要明白它们的定义和用途。糗事百科是一个以分享笑话、奇闻异事、搞笑图片和视频为主的社交平台,而内涵段子则是一个以幽默段子、内涵图和搞笑视频为主的社交平台。尽管它们的主要内容不同,但它们的目标都是让用户笑声不断。
实际上,糗事百科和内涵段子可以被视为是同一类的娱乐平台,因为它们的用户群体有很多的交叉。很多人同时在这两个平台上发表内容或是消费娱乐内容。这是因为糗事百科和内涵段子提供了不同的笑点和娱乐形式,满足了不同用户的需求。
糗事百科和内涵段子之间的关系可以用一个简单的类比来说明。可以把糗事百科看作是一个大杂烩,里面有各种各样的笑话、搞笑图片和视频,而内涵段子则是糗事百科中的一个分支,更加专注于幽默段子和内涵图。换句话说,内涵段子可以被认为是糗事百科的一部分,但糗事百科不仅仅局限于内涵段子的内容。
糗事百科和内涵段子的独特之处
虽然糗事百科和内涵段子有一些共同之处,但它们各自都有独特的特点。
糗事百科最大的特点是其内容的多样性。用户可以在糗事百科上找到各种各样的笑话、奇闻异事、搞笑图片和视频。这些内容不仅包括用户自己的创作,还包括用户转发的、自媒体的、娱乐明星相关的以及其他笑点的内容。这种多样性使得糗事百科成为一个极具娱乐性和创造性的平台。
相比之下,内涵段子更加专注于幽默段子和内涵图。它的特点在于创作者们的独立创作和审核机制。内涵段子上的内容大多是用户自己原创的,这使得整个平台充满了个人特色和创意。此外,内涵段子的审核机制也十分严格,以保证内容的质量和合法性。这就意味着用户在内涵段子上能够获得更加精心挑选和筛选的娱乐内容。
糗事百科和内涵段子的受众群体
糗事百科和内涵段子的受众群体有一些交叉,但也存在一些差异。
糗事百科的受众群体非常广泛。无论是男性还是女性,无论是年轻人还是老年人,都可以在糗事百科上找到自己喜欢的笑话和搞笑内容。糗事百科提供了一个娱乐和放松的平台,让人们在忙碌的生活中寻找一些乐趣和轻松。
内涵段子的受众群体主要是一些年轻人和搞笑爱好者。内涵段子的幽默段子和内涵图往往具有一定的文化内涵和时代特点,更能吸引年轻人的关注。同时,内涵段子的创作者们也善于运用网络流行语和梗,与年轻人的生活方式和口味相契合。
结论
综上所述,糗事百科和内涵段子虽然有所关联,但它们是两个独立而又互补的娱乐平台。
糗事百科的内容更加多样化,涵盖了各种各样的笑点和娱乐形式,适合不同用户的需求。而内涵段子则更加专注于幽默段子和内涵图,具有较高的创作者个性化和内容审核标准。两者都有自己的受众群体,但也存在一些重叠。
无论是糗事百科还是内涵段子,它们都扮演着让人们笑声不断的角色。无论您是喜欢更广泛笑点还是更专注内涵段子的人,这两个平台都将带给您无尽的欢乐和娱乐。尽情享受其中的乐趣吧!
六、python爬取app数据库
使用Python爬取APP数据库的方法
在当今的移动应用市场中,大量的数据隐藏在各种APP的数据库中。为了获取这些有价值的数据并进行进一步的分析,使用Python编写爬虫是一种高效且便捷的方法。
1. 安装必要的库
在开始之前,我们需要先安装一些Python库,用于爬取APP数据库。其中最重要的是以下两个库:
- Beautiful Soup: 用于解析和XML文档,是爬虫中常用的库。
- Requests: 用于发送HTTP请求,获取APP数据库相关的响应。
我们可以使用pip来安装这些库:
pip install beautifulsoup4
pip install requests
2. 分析APP的网络请求
在爬取APP数据库之前,我们需要分析APP的网络请求,以便确定如何获取数据。通常,APP会通过发送HTTP请求与服务器进行通信,并从服务器获取所需的数据。
可以使用开发者工具(如Chrome开发者工具)来监视APP的网络请求。通过查看请求和响应的详细信息,我们可以了解APP与服务器之间的通信。
3. 发送HTTP请求
在Python中,我们可以使用Requests库来发送HTTP请求,并获取APP数据库相关的响应。以下是一个示例代码:
import requests
url = 'e.com/api/database'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
database_content = response.text
# 对获取到的数据库内容进行处理
# ...
在上面的代码中,我们使用了Requests库发送了一个GET请求,并传递了一个headers参数,以模拟浏览器发送请求的行为。获取到的响应内容可以通过response.text来获取。
4. 解析数据库内容
使用Beautiful Soup库来解析获取到的数据库内容是非常方便的。我们可以使用这个库的各种功能来提取所需的数据,包括查找特定的标签、获取标签内的文本、提取属性等等。
以下是一个简单的示例代码,用于从获取到的数据库内容中提取出所有的用户名:
from bs4 import BeautifulSoup
# 假设获取到的数据库内容为database_content
soup = BeautifulSoup(database_content, 'html.parser')
usernames = []
user_elements = soup.find_all('span', class_='username')
for user_element in user_elements:
usernames.append(user_element.text)
在上述示例代码中,我们使用了Beautiful Soup的find_all方法来查找所有符合条件的标签,并通过text属性获取标签内的文本。
5. 数据存储和进一步处理
获取到所需的数据后,我们可以将其存储到文件或者进行进一步的处理和分析。Python提供了许多库和工具,用于数据存储和处理,如Pandas、NumPy等。
以下是一个示例代码,用于将获取到的用户名存储到CSV文件中:
import csv
# 假设获取到的用户名列表为usernames
data = [[user] for user in usernames]
with open('usernames.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)
在上述示例代码中,我们使用了CSV库来将数据存储到CSV文件中。你也可以根据需要选择其他格式的数据存储方式。
总结
使用Python编写爬虫来获取APP数据库是一种高效且便捷的方法。通过分析APP的网络请求,发送HTTP请求并使用Beautiful Soup库来解析数据库内容,我们可以轻松地提取所需的数据并进行进一步的处理和分析。
在进行APP数据库爬取时,需要注意遵守法律法规和相关隐私政策,确保数据获取的合法性。
七、python爬取图片的好处?
可以批量获取所需的图片,减少不必要的人工费时操作
八、python 爬取新笔趣阁小说有哪些推荐?
嗨嗨,我是小圆。
相信大家都会看小说,但是有些小说看几章就要付费,奈何自己又没有会员,只能用用python爬取一下了。
基本开发环境
Python 3.6Pycharm
相关模块的使用
requestsparsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取
一、明确需求爬取小说内容保存到本地
- 小说名字
- 小说章节名字
- 小说内容
# 第一章小说url地址
url = 'http://www.biquges.com/52_52642/25585323.html'url = 'http://www.biquges.com/52_52642/25585323.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding解析数据
根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
print(title, content_str)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/25585323.html'
get_one_novel(url)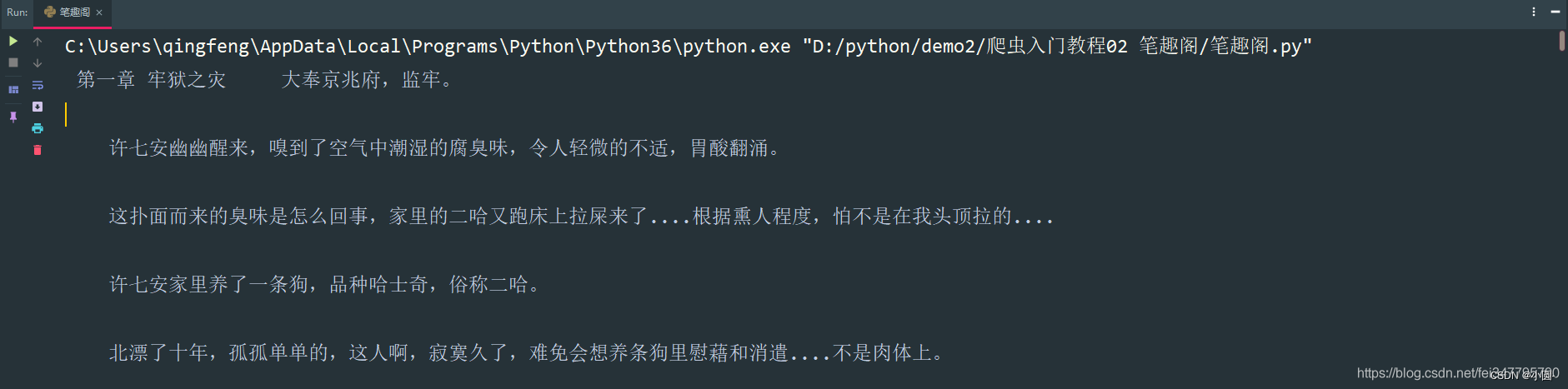保存数据(数据持久化)
使用常用的保存方式: with open
def save(title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
# 路径
filename = f'{title}\\'
# os 内置模块,自动创建文件夹
if os.makedirs(filename):
os.mkdir()
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)保存一章小说,就这样写完了,如果想要保存整本小说呢?
整本小说爬虫
既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
for dd in dds:
novel_url = 'http://www.biquges.com' + dd
print(novel_url)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/index.html'
get_all_url(url)这样就获取了所有的小说章节url地址了。
爬取全本完整代码
import requests
import parsel
from tqdm import tqdm
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def save(novel_name, title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
filename = f'{novel_name}' + '.txt'
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename, mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)
def get_one_novel(name, novel_url):
# 调用请求网页数据函数
response = get_response(novel_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
save(name, title, content_str)
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
# 小说名字
novel_name = selector.css('#info h1::text').get()
for dd in tqdm(dds):
novel_url = 'http://www.biquges.com' + dd
get_one_novel(novel_name, novel_url)
if __name__ == '__main__':
novel_id = input('输入书名ID:')
url = f'http://www.biquges.com/{novel_id}/index.html'
get_all_url(url)好了,分享到这里就结束了,感兴趣的朋友赶紧去试试吧!
喜欢的话记得给我一个关注和点赞哦
九、python怎么爬取rar文件?
由于rar通常为window下使用,须要额外的Python包rarfile。
十、python爬虫如何翻页爬取?
一般而言,Python爬虫翻页爬取的过程分为以下步骤:
分析网页:分析要爬取的网站的URL规律,了解其翻页方式,找出每一页的URL。
获取HTML:使用Python中的网络库(如requests)获取每一页的HTML源码。
解析HTML:使用HTML解析库(如BeautifulSoup)解析每一页的HTML源码,提取所需数据。
存储数据:将提取到的数据存储到本地文件或数据库中。
翻页:按照网站的翻页规则,构造下一页的URL,返回第1步重复以上步骤,直至翻完所有页。
具体实现方法可以根据不同网站的翻页规律进行相应的调整。
热点信息
-
在Python中,要查看函数的用法,可以使用以下方法: 1. 使用内置函数help():在Python交互式环境中,可以直接输入help(函数名)来获取函数的帮助文档。例如,...
-
一、java 连接数据库 在当今信息时代,Java 是一种广泛应用的编程语言,尤其在与数据库进行交互的过程中发挥着重要作用。无论是在企业级应用开发还是...
-
一、idea连接mysql数据库 php connect_error) { die("连接失败: " . $conn->connect_error);}echo "成功连接到MySQL数据库!";// 关闭连接$conn->close();?> 二、idea连接mysql数据库连...
-
要在Python中安装modbus-tk库,您可以按照以下步骤进行操作: 1. 确保您已经安装了Python解释器。您可以从Python官方网站(https://www.python.org)下载和安装最新版本...