python
爬取微信小程序
一、爬取微信小程序
爬取微信小程序是一项涉及网络爬虫技术的任务,旨在获取和分析微信小程序中的数据。随着微信小程序在移动应用市场上的日益普及,越来越多的开发者和研究人员开始关注如何爬取微信小程序中的信息,以便进行商业分析、用户行为研究等工作。
爬取目的
通过爬取微信小程序,可以获取到丰富的数据,包括但不限于小程序名称、描述、开发者信息、页面结构、用户评论等内容。这些数据可以帮助开发者了解当前市场上的热门小程序、用户对小程序的评价和反馈,为其自身的小程序开发和推广提供参考。
对于研究人员来说,爬取微信小程序中的数据可以用于分析用户行为模式、小程序间的竞争关系、行业发展趋势等方面。此外,政府部门也可以通过爬取微信小程序中的数据,了解当前全国范围内小程序行业的发展情况,为相关政策制定提供参考依据。
爬取方法
爬取微信小程序的方法主要包括两种:通过API接口直接获取数据,或者通过模拟用户操作实现数据抓取。前者需要开发者对微信开放平台的接口文档和授权机制较为了解,能够直接获取到小程序的基本信息。而后者需要借助网络爬虫工具,模拟用户在微信客户端中的操作步骤,从而逐步获取所需的数据。
爬取微信小程序的关键在于如何有效地识别和抓取数据。开发者需要设计合理的爬取规则,避免对目标网站造成过大的访问压力和被封IP的风险。在爬取的过程中,还需要不断优化代码,处理异常情况,确保数据的完整性和准确性。
爬取挑战
尽管爬取微信小程序具有诸多优势和应用前景,但也面临着一些挑战和限制。首先,微信小程序的数据访问权限受到一定的限制,开发者需要遵守相关规定和政策,避免影响到用户体验和小程序的正常运行。其次,微信小程序的数据结构多样化,爬取过程中可能遇到页面反爬措施或数据加密等问题,需要具备较强的技术能力和解决方案。
此外,爬取微信小程序的过程中可能涉及到法律和道德方面的问题。如果爬取行为违反了相关法律法规或侵犯了他人的合法权益,开发者可能会面临法律诉讼或道德谴责。因此,在进行爬取微信小程序的过程中,务必要遵守法律法规,注重数据隐私和合法性。
总结
总的来说,爬取微信小程序是一项具有潜力和挑战并存的任务。通过合理的爬取方法和技术手段,可以获取到有价值的数据信息,为相关的研究和应用提供支持和参考。但是在进行爬取的过程中,需要谨慎对待数据的使用和保护,遵守相关的法律和规定,才能更好地发挥数据爬取的作用。
二、怎样用python爬取网页?
可以使用Python中urllib和BeautifulSoup库来爬取网页。urllib库可用于发送HTTP请求并获取响应,而BeautifulSoup库可用于解析和提取HTML文档中的数据。通过将这两个库结合起来,可以编写脚本以自动化地从网页中提取所需信息。
三、Python可以爬取网易云VIP音乐吗?
最近一个朋友和我聊天的时候说想听一首歌,可是要会员,问我要怎么才能下载下来。。因为前几天群里一个朋友刚发了一个python爬取图片的爬虫,于是我打开了他写的代码,仔细研究了一下后,我根据他写的代码,进行了一系列的改造,最终完成了这个python爬取音乐的爬虫~~
python爬虫下载会员音乐
安装python环境
第一步肯定是安装一个python环境啦。。因为网上教程很多,就不多说了,可以自行搜索安装方法的。
其次就是安装IDE啦。推荐:pycharm,如果你想用txt文本写也可以。
开始写代码啦
引入需要的包
import requests
from lxml import etree进入正题了
定义两个变量用来保存url
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="利用requests库向网站发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")接下来就要遍历获取到的url列表,下载服务器上的歌曲了
for data in id_list:
#获取歌曲的链接
href = data.xpath("./@href")[0]
#把链接进行分隔
music_id = href.split("=")[1]
#获取歌曲名称
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
#请求歌曲下载地址
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)那就开始正式下载网易云音乐吧~~~
下面就把完整代码贴出来吧~
import requests
from lxml import etree
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="
#向网址发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")
for data in id_list:
href = data.xpath("./@href")[0]
music_id = href.split("=")[1]
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)
#学习加喂:lbt13732741834此代码仅供学习使用,请勿用于商业用途
学习加喂:lbt13732741834
我很刑 | 用python爬了一万首会员歌曲四、python爬取图片的好处?
可以批量获取所需的图片,减少不必要的人工费时操作
五、怎样用python爬取需要的文献?
如果你需要用 Python 爬取文献,你可以使用一些 Python 的爬虫库,如 BeautifulSoup、Scrapy、Request 等。以下是一个简单的示例,使用 BeautifulSoup 和 Request 库爬取网页上的文献信息:
import requests
from bs4 import BeautifulSoup
def crawl_papers(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 查找需要的文献信息
papers = soup.find_all('div', class_='paper')
for paper in papers:
title = paper.find('h3').text
author = paper.find('p', class_='authors').text
publication = paper.find('p', class_='publication').text
abstract = paper.find('p', class_='abstract').text
# 打印文献信息
print(f'标题:{title}')
print(f'作者:{author}')
print(f'出版物:{publication}')
print(f'摘要:{abstract}')
print('-' * 20)
# 爬取文献的 URL
url = 'https://example.com/papers'
crawl_papers(url)
在这个示例中,我们首先发送一个 HTTP 请求获取网页内容,然后使用 BeautifulSoup 库解析网页 HTML 代码。我们查找具有特定 class(如 paper )的 div 元素,然后提取其中的文献信息,包括标题、作者、出版物和摘要。最后,我们打印出每个文献的信息。
请注意,爬取文献信息时需要遵守相关的法律和规定,确保你有合法的权限和许可。此外,一些网站可能会实施反爬虫机制,因此在爬取文献信息时要小心处理请求频率和其他限制。
六、python 爬取新笔趣阁小说有哪些推荐?
嗨嗨,我是小圆。
相信大家都会看小说,但是有些小说看几章就要付费,奈何自己又没有会员,只能用用python爬取一下了。
基本开发环境
Python 3.6Pycharm
相关模块的使用
requestsparsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取
一、明确需求爬取小说内容保存到本地
- 小说名字
- 小说章节名字
- 小说内容
# 第一章小说url地址
url = 'http://www.biquges.com/52_52642/25585323.html'url = 'http://www.biquges.com/52_52642/25585323.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding解析数据
根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
print(title, content_str)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/25585323.html'
get_one_novel(url)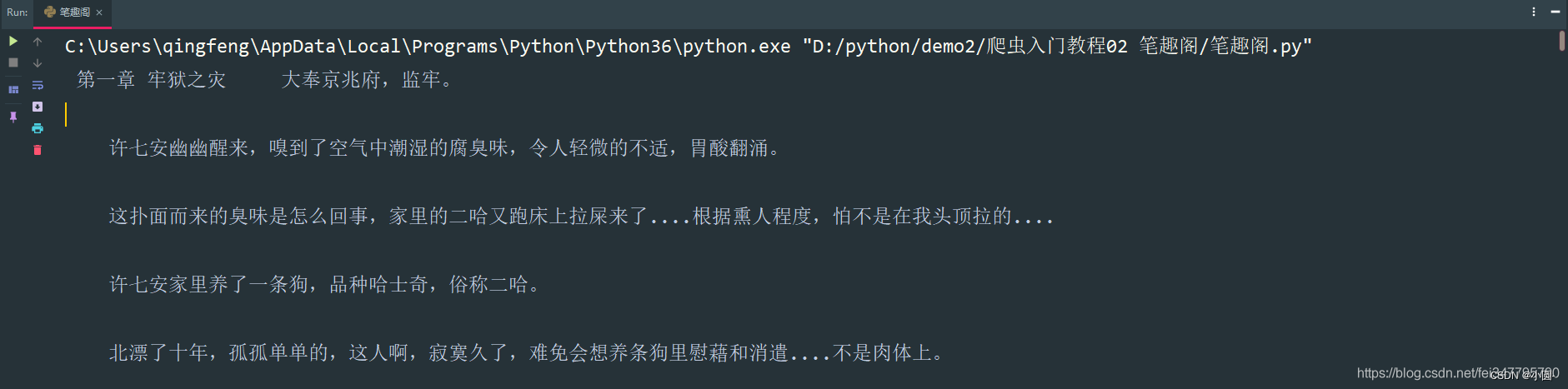保存数据(数据持久化)
使用常用的保存方式: with open
def save(title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
# 路径
filename = f'{title}\\'
# os 内置模块,自动创建文件夹
if os.makedirs(filename):
os.mkdir()
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)保存一章小说,就这样写完了,如果想要保存整本小说呢?
整本小说爬虫
既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
for dd in dds:
novel_url = 'http://www.biquges.com' + dd
print(novel_url)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/index.html'
get_all_url(url)这样就获取了所有的小说章节url地址了。
爬取全本完整代码
import requests
import parsel
from tqdm import tqdm
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def save(novel_name, title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
filename = f'{novel_name}' + '.txt'
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename, mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)
def get_one_novel(name, novel_url):
# 调用请求网页数据函数
response = get_response(novel_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
save(name, title, content_str)
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
# 小说名字
novel_name = selector.css('#info h1::text').get()
for dd in tqdm(dds):
novel_url = 'http://www.biquges.com' + dd
get_one_novel(novel_name, novel_url)
if __name__ == '__main__':
novel_id = input('输入书名ID:')
url = f'http://www.biquges.com/{novel_id}/index.html'
get_all_url(url)好了,分享到这里就结束了,感兴趣的朋友赶紧去试试吧!
喜欢的话记得给我一个关注和点赞哦
七、python怎么爬取rar文件?
由于rar通常为window下使用,须要额外的Python包rarfile。
八、python爬虫如何翻页爬取?
一般而言,Python爬虫翻页爬取的过程分为以下步骤:
分析网页:分析要爬取的网站的URL规律,了解其翻页方式,找出每一页的URL。
获取HTML:使用Python中的网络库(如requests)获取每一页的HTML源码。
解析HTML:使用HTML解析库(如BeautifulSoup)解析每一页的HTML源码,提取所需数据。
存储数据:将提取到的数据存储到本地文件或数据库中。
翻页:按照网站的翻页规则,构造下一页的URL,返回第1步重复以上步骤,直至翻完所有页。
具体实现方法可以根据不同网站的翻页规律进行相应的调整。
九、如何用python爬取数据?
使用Python爬取数据需要掌握以下几个步骤:
1. 确定目标网站:确定要爬取的数据来源,可以通过搜索引擎、网络信息抓取工具等途径找到目标网站。
2. 获取网页内容:使用Python中的requests库发送HTTP请求,获取目标网站的网页内容。
3. 解析网页内容:使用Python中的BeautifulSoup库解析网页内容,提取需要的数据。
4. 保存数据:将提取到的数据保存到本地文件中,可以使用Python中的csv、excel等库将数据保存为文件格式。
下面是一个简单的示例代码,演示如何使用Python爬取一个网站的数据:
```python
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求获取网页内容
url = 'http://example.com'
response = requests.get(url)
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取需要的数据并保存到本地文件中
with open('data.csv', 'w', encoding='utf-8') as f:
f.write(soup.prettify())
```
上述代码中,首先使用requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析网页内容,提取需要的数据并保存到本地文件中。具体来说,代码中使用了BeautifulSoup的prettify()方法将网页内容打印到本地文件中。需要注意的是,上述代码中使用了utf-8编码保存文件,确保能够正确保存网页内容。
需要注意的是,爬取数据时需要遵守网站的使用规则和法律法规,避免侵犯他人的合法权益和版权问题。同时,对于一些敏感或禁止爬取的数据,需要谨慎处理,避免触犯相关法律法规。
十、python爬取app数据库
使用Python爬取APP数据库的方法
在当今的移动应用市场中,大量的数据隐藏在各种APP的数据库中。为了获取这些有价值的数据并进行进一步的分析,使用Python编写爬虫是一种高效且便捷的方法。
1. 安装必要的库
在开始之前,我们需要先安装一些Python库,用于爬取APP数据库。其中最重要的是以下两个库:
- Beautiful Soup: 用于解析和XML文档,是爬虫中常用的库。
- Requests: 用于发送HTTP请求,获取APP数据库相关的响应。
我们可以使用pip来安装这些库:
pip install beautifulsoup4
pip install requests
2. 分析APP的网络请求
在爬取APP数据库之前,我们需要分析APP的网络请求,以便确定如何获取数据。通常,APP会通过发送HTTP请求与服务器进行通信,并从服务器获取所需的数据。
可以使用开发者工具(如Chrome开发者工具)来监视APP的网络请求。通过查看请求和响应的详细信息,我们可以了解APP与服务器之间的通信。
3. 发送HTTP请求
在Python中,我们可以使用Requests库来发送HTTP请求,并获取APP数据库相关的响应。以下是一个示例代码:
import requests
url = 'e.com/api/database'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
database_content = response.text
# 对获取到的数据库内容进行处理
# ...
在上面的代码中,我们使用了Requests库发送了一个GET请求,并传递了一个headers参数,以模拟浏览器发送请求的行为。获取到的响应内容可以通过response.text来获取。
4. 解析数据库内容
使用Beautiful Soup库来解析获取到的数据库内容是非常方便的。我们可以使用这个库的各种功能来提取所需的数据,包括查找特定的标签、获取标签内的文本、提取属性等等。
以下是一个简单的示例代码,用于从获取到的数据库内容中提取出所有的用户名:
from bs4 import BeautifulSoup
# 假设获取到的数据库内容为database_content
soup = BeautifulSoup(database_content, 'html.parser')
usernames = []
user_elements = soup.find_all('span', class_='username')
for user_element in user_elements:
usernames.append(user_element.text)
在上述示例代码中,我们使用了Beautiful Soup的find_all方法来查找所有符合条件的标签,并通过text属性获取标签内的文本。
5. 数据存储和进一步处理
获取到所需的数据后,我们可以将其存储到文件或者进行进一步的处理和分析。Python提供了许多库和工具,用于数据存储和处理,如Pandas、NumPy等。
以下是一个示例代码,用于将获取到的用户名存储到CSV文件中:
import csv
# 假设获取到的用户名列表为usernames
data = [[user] for user in usernames]
with open('usernames.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)
在上述示例代码中,我们使用了CSV库来将数据存储到CSV文件中。你也可以根据需要选择其他格式的数据存储方式。
总结
使用Python编写爬虫来获取APP数据库是一种高效且便捷的方法。通过分析APP的网络请求,发送HTTP请求并使用Beautiful Soup库来解析数据库内容,我们可以轻松地提取所需的数据并进行进一步的处理和分析。
在进行APP数据库爬取时,需要注意遵守法律法规和相关隐私政策,确保数据获取的合法性。
热点信息
-
在Python中,要查看函数的用法,可以使用以下方法: 1. 使用内置函数help():在Python交互式环境中,可以直接输入help(函数名)来获取函数的帮助文档。例如,...
-
一、java 连接数据库 在当今信息时代,Java 是一种广泛应用的编程语言,尤其在与数据库进行交互的过程中发挥着重要作用。无论是在企业级应用开发还是...
-
一、idea连接mysql数据库 php connect_error) { die("连接失败: " . $conn->connect_error);}echo "成功连接到MySQL数据库!";// 关闭连接$conn->close();?> 二、idea连接mysql数据库连...
-
要在Python中安装modbus-tk库,您可以按照以下步骤进行操作: 1. 确保您已经安装了Python解释器。您可以从Python官方网站(https://www.python.org)下载和安装最新版本...