python
美团怎么隐藏订单信息?
一、美团怎么隐藏订单信息?
我们打开美团之后,点击你所需要隐藏的商品,点击鼠标左键即可将其隐藏!
二、美团订单如何修改信息?
在订单页下面有个修改订单信息,可以修改地址或者电话都可以。
三、Python可以爬取网易云VIP音乐吗?
最近一个朋友和我聊天的时候说想听一首歌,可是要会员,问我要怎么才能下载下来。。因为前几天群里一个朋友刚发了一个python爬取图片的爬虫,于是我打开了他写的代码,仔细研究了一下后,我根据他写的代码,进行了一系列的改造,最终完成了这个python爬取音乐的爬虫~~
python爬虫下载会员音乐
安装python环境
第一步肯定是安装一个python环境啦。。因为网上教程很多,就不多说了,可以自行搜索安装方法的。
其次就是安装IDE啦。推荐:pycharm,如果你想用txt文本写也可以。
开始写代码啦
引入需要的包
import requests
from lxml import etree进入正题了
定义两个变量用来保存url
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="利用requests库向网站发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")接下来就要遍历获取到的url列表,下载服务器上的歌曲了
for data in id_list:
#获取歌曲的链接
href = data.xpath("./@href")[0]
#把链接进行分隔
music_id = href.split("=")[1]
#获取歌曲名称
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
#请求歌曲下载地址
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)那就开始正式下载网易云音乐吧~~~
下面就把完整代码贴出来吧~
import requests
from lxml import etree
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="
#向网址发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")
for data in id_list:
href = data.xpath("./@href")[0]
music_id = href.split("=")[1]
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)
#学习加喂:lbt13732741834此代码仅供学习使用,请勿用于商业用途
学习加喂:lbt13732741834
我很刑 | 用python爬了一万首会员歌曲四、美团如何查询差评订单信息?
一、差评的显示时间
饿了么的评价是实时显示的(所以商家要经常查看饿了么的顾客评价,及时发现差评)。
美团的评价是第二天显示(即:当日评价次日显示)。
并且在订单完成48小时后,才会在评价里展示订单里的菜品清单。
二、如何锁定差评的具体订单?
1、美团
商家可以从评价里摘取几个关键信息进行订单筛选:
A.配送是否有超时
B.顾客赞或踩的菜品(通过订单比对,缩小范围)
C.评论里显示的顾客分类(新老顾客)
通过这3点信息对近两日内的订单进行交叉对比,就能找到差评的具体订单了。
五、怎么看美团订单全部信息?
1.
首先,打开美团,点击右下角我的
2.
点击全部
3.
即可查看全部的订单信息
六、python爬取图片的好处?
可以批量获取所需的图片,减少不必要的人工费时操作
七、python 爬取新笔趣阁小说有哪些推荐?
嗨嗨,我是小圆。
相信大家都会看小说,但是有些小说看几章就要付费,奈何自己又没有会员,只能用用python爬取一下了。
基本开发环境
Python 3.6Pycharm
相关模块的使用
requestsparsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取
一、明确需求爬取小说内容保存到本地
- 小说名字
- 小说章节名字
- 小说内容
# 第一章小说url地址
url = 'http://www.biquges.com/52_52642/25585323.html'url = 'http://www.biquges.com/52_52642/25585323.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding解析数据
根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
print(title, content_str)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/25585323.html'
get_one_novel(url)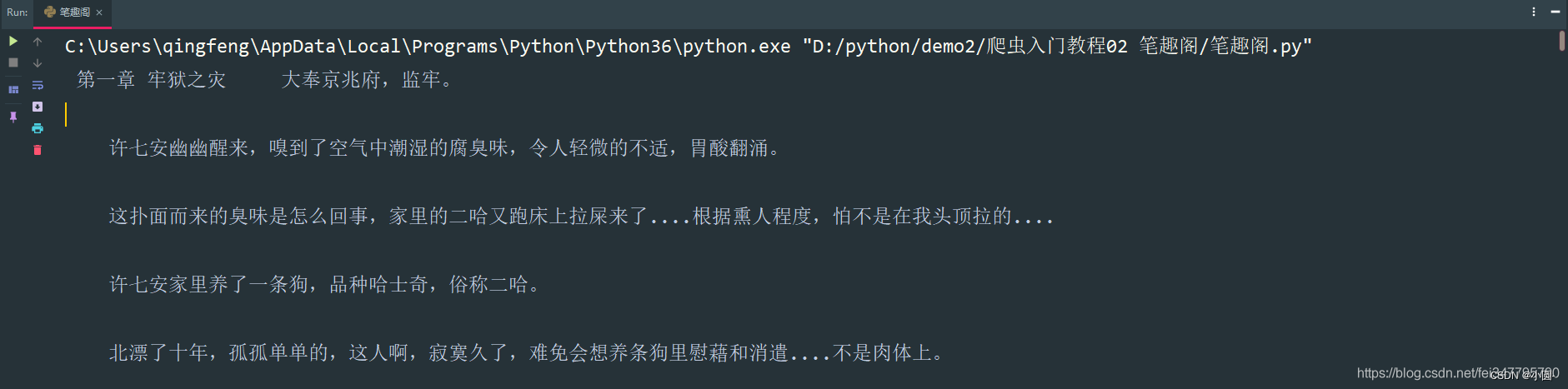保存数据(数据持久化)
使用常用的保存方式: with open
def save(title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
# 路径
filename = f'{title}\\'
# os 内置模块,自动创建文件夹
if os.makedirs(filename):
os.mkdir()
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)保存一章小说,就这样写完了,如果想要保存整本小说呢?
整本小说爬虫
既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
for dd in dds:
novel_url = 'http://www.biquges.com' + dd
print(novel_url)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/index.html'
get_all_url(url)这样就获取了所有的小说章节url地址了。
爬取全本完整代码
import requests
import parsel
from tqdm import tqdm
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def save(novel_name, title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
filename = f'{novel_name}' + '.txt'
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename, mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)
def get_one_novel(name, novel_url):
# 调用请求网页数据函数
response = get_response(novel_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
save(name, title, content_str)
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
# 小说名字
novel_name = selector.css('#info h1::text').get()
for dd in tqdm(dds):
novel_url = 'http://www.biquges.com' + dd
get_one_novel(novel_name, novel_url)
if __name__ == '__main__':
novel_id = input('输入书名ID:')
url = f'http://www.biquges.com/{novel_id}/index.html'
get_all_url(url)好了,分享到这里就结束了,感兴趣的朋友赶紧去试试吧!
喜欢的话记得给我一个关注和点赞哦
八、python怎么爬取rar文件?
由于rar通常为window下使用,须要额外的Python包rarfile。
九、python爬虫如何翻页爬取?
一般而言,Python爬虫翻页爬取的过程分为以下步骤:
分析网页:分析要爬取的网站的URL规律,了解其翻页方式,找出每一页的URL。
获取HTML:使用Python中的网络库(如requests)获取每一页的HTML源码。
解析HTML:使用HTML解析库(如BeautifulSoup)解析每一页的HTML源码,提取所需数据。
存储数据:将提取到的数据存储到本地文件或数据库中。
翻页:按照网站的翻页规则,构造下一页的URL,返回第1步重复以上步骤,直至翻完所有页。
具体实现方法可以根据不同网站的翻页规律进行相应的调整。
十、如何用python爬取数据?
使用Python爬取数据需要掌握以下几个步骤:
1. 确定目标网站:确定要爬取的数据来源,可以通过搜索引擎、网络信息抓取工具等途径找到目标网站。
2. 获取网页内容:使用Python中的requests库发送HTTP请求,获取目标网站的网页内容。
3. 解析网页内容:使用Python中的BeautifulSoup库解析网页内容,提取需要的数据。
4. 保存数据:将提取到的数据保存到本地文件中,可以使用Python中的csv、excel等库将数据保存为文件格式。
下面是一个简单的示例代码,演示如何使用Python爬取一个网站的数据:
```python
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求获取网页内容
url = 'http://example.com'
response = requests.get(url)
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取需要的数据并保存到本地文件中
with open('data.csv', 'w', encoding='utf-8') as f:
f.write(soup.prettify())
```
上述代码中,首先使用requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup库解析网页内容,提取需要的数据并保存到本地文件中。具体来说,代码中使用了BeautifulSoup的prettify()方法将网页内容打印到本地文件中。需要注意的是,上述代码中使用了utf-8编码保存文件,确保能够正确保存网页内容。
需要注意的是,爬取数据时需要遵守网站的使用规则和法律法规,避免侵犯他人的合法权益和版权问题。同时,对于一些敏感或禁止爬取的数据,需要谨慎处理,避免触犯相关法律法规。
热点信息
-
在Python中,要查看函数的用法,可以使用以下方法: 1. 使用内置函数help():在Python交互式环境中,可以直接输入help(函数名)来获取函数的帮助文档。例如,...
-
一、java 连接数据库 在当今信息时代,Java 是一种广泛应用的编程语言,尤其在与数据库进行交互的过程中发挥着重要作用。无论是在企业级应用开发还是...
-
一、idea连接mysql数据库 php connect_error) { die("连接失败: " . $conn->connect_error);}echo "成功连接到MySQL数据库!";// 关闭连接$conn->close();?> 二、idea连接mysql数据库连...
-
要在Python中安装modbus-tk库,您可以按照以下步骤进行操作: 1. 确保您已经安装了Python解释器。您可以从Python官方网站(https://www.python.org)下载和安装最新版本...