python
怎么用python爬取信息?
一、怎么用python爬取信息?
Python有很多用于爬取信息的库和工具,其中最常用的是BeautifulSoup和Scrapy。
以下是使用BeautifulSoup和Scrapy爬取网页信息的基本步骤:
1. 安装所需的库:
```python
pip install beautifulsoup4
pip install Scrapy
```
2. 编写一个Scrapy爬虫文件:
在Scrapy的文档中,可以找到许多用于编写爬虫文件的模板。下面是一个基本的示例:
```python
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from example.items import ExampleItem
class MySpider(CrawlSpider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
rules = (Rule(LinkExtractor(allow=('item/\d+',)), callback='parse_item', follow=True),)
def parse_item(self, response):
item = ExampleItem()
item['url'] = response.url
item['title'] = response.xpath('//title/text()').get()
item['description'] = response.xpath('//meta[@name="description"]/@content').get()
yield item
```
在这个示例中,我们创建了一个名为“example”的爬虫,并指定了允许访问的域名和起始URL。我们还定义了一个名为“parse_item”的方法,该方法将解析每个页面并提取所需的信息。在这个方法中,我们创建了一个名为“ExampleItem”的自定义项类,该项类包含我们要从页面中提取的所有字段。最后,我们使用yield语句将每个项返回给爬虫。
3. 运行爬虫:
在命令行中运行以下命令:
```shell
scrapy runspider spider.py
```
这将启动爬虫并开始从指定的URL开始爬取网页。
二、怎样用python爬取网页?
可以使用Python中urllib和BeautifulSoup库来爬取网页。urllib库可用于发送HTTP请求并获取响应,而BeautifulSoup库可用于解析和提取HTML文档中的数据。通过将这两个库结合起来,可以编写脚本以自动化地从网页中提取所需信息。
三、python 爬去app数据
使用Python爬取App数据的方法介绍
在当今数字化的时代,移动应用程序(App)已经成为人们生活中不可或缺的一部分。对于开发者和市场营销人员来说,了解关于App的数据是至关重要的,这可以提供有关用户行为、市场趋势和竞争对手分析的宝贵信息。本文将介绍使用Python爬取App数据的方法,帮助您获取这些有用的数据。
为什么选择Python?
在众多的编程语言中,为什么我们选择Python来进行App数据爬取呢?原因有以下几点:
- 简单易学:Python是一种简单且易于学习的编程语言,具有清晰的语法和逻辑结构。即使是初学者也能迅速上手。
- 丰富的库支持:Python拥有广泛且强大的第三方库,尤其是在数据处理和网络爬虫方面。这使得使用Python来进行App数据爬取非常便捷。
- 跨平台兼容:Python可以在多个操作系统上运行,包括Windows、macOS和Linux。这为不同环境下的数据爬取提供了便利。
Python爬取App数据的步骤
下面是使用Python爬取App数据的一般步骤:
- 确定目标:首先,您需要确定要爬取的App。可以根据自己的需求选择特定的App,例如社交媒体应用、电子商务应用或游戏应用。
- 分析数据:在开始爬取之前,需要分析要获取的数据。这包括确定所需的字段、数据结构和爬取的网站或API。
- 获取许可:某些App可能有访问限制或需要API密钥。在开始爬取之前,确保您已经获取了必要的许可。
- 编写爬虫:使用Python编写爬虫程序。根据目标App的特定结构和网站/ API的规则,编写相关的代码以获取所需的数据。
- 数据清洗和处理:获取到原始数据后,您可能需要进行数据清洗和处理。这可以包括删除重复数据、填充缺失值和转换数据类型等操作。
- 存储数据:将清洗和处理后的数据存储到适当的格式中,例如CSV文件、数据库或在线数据仓库。
- 分析和可视化:利用Python的数据分析和可视化库,对爬取的App数据进行深入分析和可视化,以发现有用的信息和洞察。
使用Python库进行App数据爬取
Python拥有许多强大的库,可以帮助您更轻松地进行App数据爬取。以下是一些常用的库:
- Beautiful Soup:用于解析和XML文档,从中提取所需的数据。
- Selenium:用于自动化Web浏览器,模拟用户操作以获取动态生成的内容。
- Requests:用于发送HTTP请求并获取响应,可用于与API进行交互。
- Scrapy:一个强大的网络爬虫框架,可用于快速构建和扩展爬虫程序。
- Pandas:用于数据处理和分析的强大库,可帮助您清洗和处理爬取到的数据。
- Matplotlib:用于绘制各种类型的图形和图表,可以方便地进行数据可视化。
通过整合这些库,您可以针对不同的App进行灵活、高效的数据爬取。
法律和伦理问题
在进行App数据爬取时,需要注意相关法律和伦理问题:
- 合法性:确保您的爬取行为符合适用的法律法规。一些国家或地区可能对数据爬取有限制或要求特定的许可。
- 隐私保护:尊重用户隐私,并遵守适用的隐私政策。避免收集或使用个人身份信息(PII),除非您有合法的授权。
- 数据用途:在使用爬取到的App数据时,确保合法和合理的用途。遵循数据保护和使用的最佳实践。
结论
Python作为一种功能强大且易于使用的编程语言,为App数据爬取提供了巨大的便利。通过使用Python库,您可以轻松地抓取和分析App数据,获得有关用户行为和市场趋势的宝贵见解。在进行App数据爬取时,请牢记法律和伦理问题,并确保遵守适用的规定。希望本文对您了解使用Python爬取App数据的方法有所帮助。
四、怎样用python爬取需要的文献?
如果你需要用 Python 爬取文献,你可以使用一些 Python 的爬虫库,如 BeautifulSoup、Scrapy、Request 等。以下是一个简单的示例,使用 BeautifulSoup 和 Request 库爬取网页上的文献信息:
import requests
from bs4 import BeautifulSoup
def crawl_papers(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 查找需要的文献信息
papers = soup.find_all('div', class_='paper')
for paper in papers:
title = paper.find('h3').text
author = paper.find('p', class_='authors').text
publication = paper.find('p', class_='publication').text
abstract = paper.find('p', class_='abstract').text
# 打印文献信息
print(f'标题:{title}')
print(f'作者:{author}')
print(f'出版物:{publication}')
print(f'摘要:{abstract}')
print('-' * 20)
# 爬取文献的 URL
url = 'https://example.com/papers'
crawl_papers(url)
在这个示例中,我们首先发送一个 HTTP 请求获取网页内容,然后使用 BeautifulSoup 库解析网页 HTML 代码。我们查找具有特定 class(如 paper )的 div 元素,然后提取其中的文献信息,包括标题、作者、出版物和摘要。最后,我们打印出每个文献的信息。
请注意,爬取文献信息时需要遵守相关的法律和规定,确保你有合法的权限和许可。此外,一些网站可能会实施反爬虫机制,因此在爬取文献信息时要小心处理请求频率和其他限制。
五、Python可以爬取网易云VIP音乐吗?
最近一个朋友和我聊天的时候说想听一首歌,可是要会员,问我要怎么才能下载下来。。因为前几天群里一个朋友刚发了一个python爬取图片的爬虫,于是我打开了他写的代码,仔细研究了一下后,我根据他写的代码,进行了一系列的改造,最终完成了这个python爬取音乐的爬虫~~
python爬虫下载会员音乐
安装python环境
第一步肯定是安装一个python环境啦。。因为网上教程很多,就不多说了,可以自行搜索安装方法的。
其次就是安装IDE啦。推荐:pycharm,如果你想用txt文本写也可以。
开始写代码啦
引入需要的包
import requests
from lxml import etree进入正题了
定义两个变量用来保存url
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="利用requests库向网站发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")接下来就要遍历获取到的url列表,下载服务器上的歌曲了
for data in id_list:
#获取歌曲的链接
href = data.xpath("./@href")[0]
#把链接进行分隔
music_id = href.split("=")[1]
#获取歌曲名称
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
#请求歌曲下载地址
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)那就开始正式下载网易云音乐吧~~~
下面就把完整代码贴出来吧~
import requests
from lxml import etree
#网易云音乐的网址
url = "https://music.163.com/discover/toplist?id=3778678"
#下载歌曲的网址,可以用第三方工具获取
url_base = "http://music.163.com/song/media/outer/url?id="
#向网址发起请求
response = requests.get(url=url)
#将获取到的HTML代码进行数据解析
html = etree.HTML(response.text)
#获取id列表
id_list = html.xpath("//a[contains(@href,'song?')]")
for data in id_list:
href = data.xpath("./@href")[0]
music_id = href.split("=")[1]
music_name = data.xpath("./text()")[0]
#拼接下载地址
music_url = url_base + music_id
music = requests.get(url=music_url)
with open("./music/%s.mp3" % music_name, "wb") as file:
file.write(music.content)
print("<%s>下载成功。。。" % music_name)
#学习加喂:lbt13732741834此代码仅供学习使用,请勿用于商业用途
学习加喂:lbt13732741834
我很刑 | 用python爬了一万首会员歌曲六、python爬取图片的好处?
可以批量获取所需的图片,减少不必要的人工费时操作
七、python爬虫什么是自动爬?
自动的。
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
八、如何用python爬汽车之家的汽车配置参数?
getComputedStyle($0).content
""紧凑型SUV""
九、python 爬取新笔趣阁小说有哪些推荐?
嗨嗨,我是小圆。
相信大家都会看小说,但是有些小说看几章就要付费,奈何自己又没有会员,只能用用python爬取一下了。
基本开发环境
Python 3.6Pycharm
相关模块的使用
requestsparsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取
一、明确需求爬取小说内容保存到本地
- 小说名字
- 小说章节名字
- 小说内容
# 第一章小说url地址
url = 'http://www.biquges.com/52_52642/25585323.html'url = 'http://www.biquges.com/52_52642/25585323.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding解析数据
根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
print(title, content_str)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/25585323.html'
get_one_novel(url)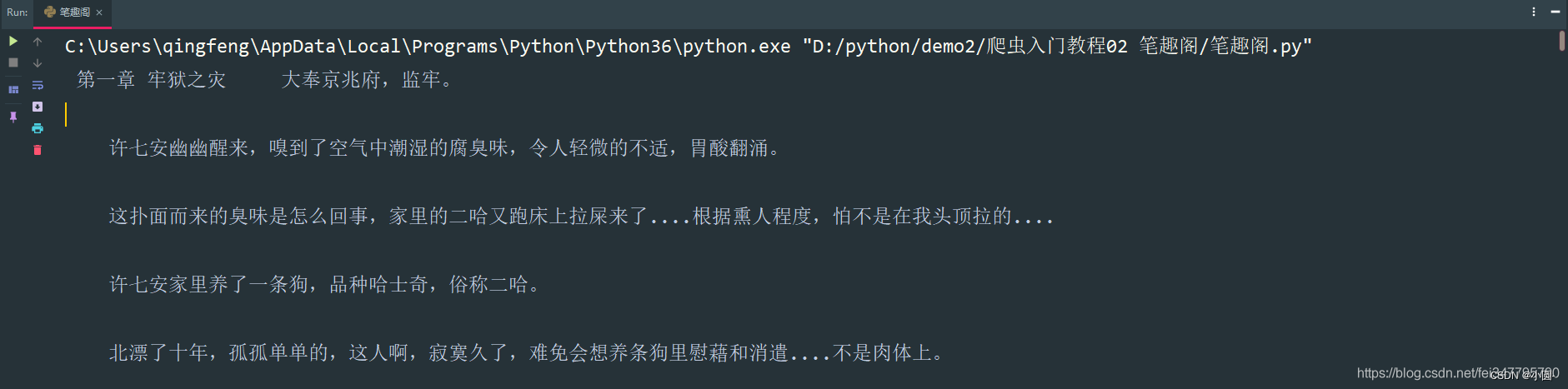保存数据(数据持久化)
使用常用的保存方式: with open
def save(title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
# 路径
filename = f'{title}\\'
# os 内置模块,自动创建文件夹
if os.makedirs(filename):
os.mkdir()
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)保存一章小说,就这样写完了,如果想要保存整本小说呢?
整本小说爬虫
既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
for dd in dds:
novel_url = 'http://www.biquges.com' + dd
print(novel_url)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/index.html'
get_all_url(url)这样就获取了所有的小说章节url地址了。
爬取全本完整代码
import requests
import parsel
from tqdm import tqdm
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def save(novel_name, title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
filename = f'{novel_name}' + '.txt'
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename, mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)
def get_one_novel(name, novel_url):
# 调用请求网页数据函数
response = get_response(novel_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
save(name, title, content_str)
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
# 小说名字
novel_name = selector.css('#info h1::text').get()
for dd in tqdm(dds):
novel_url = 'http://www.biquges.com' + dd
get_one_novel(novel_name, novel_url)
if __name__ == '__main__':
novel_id = input('输入书名ID:')
url = f'http://www.biquges.com/{novel_id}/index.html'
get_all_url(url)好了,分享到这里就结束了,感兴趣的朋友赶紧去试试吧!
喜欢的话记得给我一个关注和点赞哦
十、python怎么爬取rar文件?
由于rar通常为window下使用,须要额外的Python包rarfile。
热点信息
-
在Python中,要查看函数的用法,可以使用以下方法: 1. 使用内置函数help():在Python交互式环境中,可以直接输入help(函数名)来获取函数的帮助文档。例如,...
-
一、java 连接数据库 在当今信息时代,Java 是一种广泛应用的编程语言,尤其在与数据库进行交互的过程中发挥着重要作用。无论是在企业级应用开发还是...
-
一、idea连接mysql数据库 php connect_error) { die("连接失败: " . $conn->connect_error);}echo "成功连接到MySQL数据库!";// 关闭连接$conn->close();?> 二、idea连接mysql数据库连...
-
要在Python中安装modbus-tk库,您可以按照以下步骤进行操作: 1. 确保您已经安装了Python解释器。您可以从Python官方网站(https://www.python.org)下载和安装最新版本...