python
python3如何去除广告?
一、python3如何去除广告?
方法一:直接从软件中关闭
此类弹窗是所有弹窗广告中最“友好”的一种,在它的软件设置中给出了能够关闭这些弹窗的入口。所以,直接打开这个软件进入设置,找到弹窗的开关,直接关闭即可。
方法二:删除弹窗软件
一般情况下,此类弹窗并不是由使用的软件本身弹出的,而是在安装某个软件的时候被捆绑安装的一个单独模块。所以,只需要将这个模块直接删除即可。
1、在状态栏上右键打开“任务管理器”,也可以直接按下【Ctrl+Shift+ESC】组合键快速打开。
2、在当前进程中找到弹窗的进程,然后在这个进程上点击右键,选择【打开文件所在的位置(O)】,就可以快速定位到弹窗广告的模块。
3、删除即可。
方法三:偷梁换柱
一些弹窗模块在处理起来并没有那么容易,软件会不定期的检测这个广告模块是否存在。如果发现此模块已经被人为删除了,它就会自动下载一个新的模块。所以,这种情况下单靠删除模块的方法是行不通的,你删除多少次它就能给你重新下载多少次。
解决这种弹窗的方法就是偷梁换柱。
1、按照方法二的步骤,从任务管理器中定位到弹窗广告模块的文件夹。
2、在文件夹中找到那个弹窗模块,先复制它的文件名(一定要先复制),然后将这个文件直接删除。这样一来,软件在启动弹窗的时候就找不到了此模块了,所以弹窗也不会成功。
3、为了防止软件检测后自动下载弹窗模块,我们采用偷梁换柱之法。在当前文件夹下新建一个文本文件,它的默认名称为【新建文本文档.txt】。然后将这个文件生命名为刚复制的那个弹窗模块的文件名即可。
这样一来,软件在检测时发现广告是模块是存在的,但是却无法正常启动。
方法四:禁用软件自启动
还有一些弹窗是跟随系统启动的,每次开机都会出现这样的弹窗广告。这种又该如何解决呢?
按下【Win+R】组合键然后在运行窗口中输入“Msconfig”命令并执行。在启动项管理中将一些不必要的随机启动程序关闭。
如果是Win10系统的话,直接按下【Ctrl+Shift+ESC】组合键打开任务管理器,在“启动”选项卡中操作即可。
方法五:禁用计划任务
还有一些广告模块是按照一定的周期定时启动的,它将这个启动任务添加到了Windows的【任务计划程序库】里面了。这时就要通过Windows的【任务计划程序库】来禁止了。
在桌面上找到“计算机”然后点右键选择“管理”进入计算机管理窗口。在左侧的系统工具中依次找到“任务计划—任务计划管理库”,可以看到右侧有一些定时启动的任务。找到疑似广告弹窗的计划,然后点右键禁用。
实际上,如果没有做一些特殊设置的话,这里的计划大多都是一些应用软件的定期检测更新模块。所以,如果不确定哪个是弹窗模块的话,可以直接禁用全部计划,对系统是没有太大影响的。
二、while true如何结束循环 python3?
Python while true 使用break结束循环
Python while 循环为条件控制循环,当 while 的表达式为True时我们才进行循环,循环到表达式为False 结束。
break 与 continue 都可以退出循环,区别在于break是结束循环,continue 是跳出当前循环进入下一次循环。
三、如何通过python3写入txt文件?
使用open方法打开一个txt文件,句柄保存在f中。注意第二个参数w,表明是可写模式,只有这种模式你才可以写入文字。第一个参数大家都知道,就是文件路径,如果文件不存在,那么会自动创建一个该目录下的txt文件。 写入文字,用write 如果你一次有多行要写入,你可以用一个列表作为参数: 如果写入完毕,我们需要关闭文件,用到的close方法。 最后看一下,已经写入到tt记事本了。 open(path,'w'):w模式下,写入内容会覆盖掉原来的内容,所以我们还有另一个模式叫做追加模式,就是a模式
四、python3 编程中如何获取 MAC 地址?
在 Python 3 中获取 MAC 地址需要使用第三方库,比如 netifaces 和 uuid。
可以使用以下代码获取系统中第一个网卡的 MAC 地址:
import netifaces
import uuid
mac_addr = None
for interface in netifaces.interfaces():
try:
mac = netifaces.ifaddresses(interface)[netifaces.AF_LINK][0]['addr']
mac_addr = mac
break
except:
pass
if not mac_addr:
mac_addr = ':'.join(['{:02x}'.format((uuid.getnode() >> ele) & 0xff) for ele in range(0,8*6,8)][::-1])
print(mac_addr)这个代码会先尝试通过 netifaces 库获取第一个网卡的 MAC 地址,如果失败则使用 uuid 库生成一个伪 MAC 地址。
五、爬泰山穿越的小说?
《遮天》 作者:辰东
小说书评:主角叶凡,与十几位同学登泰山的时候意外被九龙拉棺带离地球,进入神秘的北斗星域,一路战天斗地,重组天庭,以力证道,成就天帝之位。各种打斗场景和剧情设置无比精彩,名副其实的玄幻巅峰之作。看了真是酣畅淋漓,让人感到无比舒爽。
六、爬藤月季如何爬栏杆?
爬藤月季可以通过以下步骤爬栏杆:
在栏杆旁边挖一个深度约为20cm、直径约为30cm的洞,放入肥沃的土壤。
将月季的根系放在洞里,用土壤填充均匀。
在栏杆上安装细网格网,网格大小大约为5x5cm。
将月季的藤条穿过网格,用细绳或者软布绑紧,固定在网格上。
随着月季生长,及时调整和加固藤条的绑定,以避免月季被风吹动而脱落。
定期施肥和修剪月季,促进生长和开花。
七、爬爬垫味道如何除去?
1、爬爬垫平常简易清洗,用湿毛巾直接擦干净,晾干就可以了,或者可以用两杯水加4滴洗碗用的洗洁精放入喷雾器内,喷洗垫子后,再用干布擦干。
2、如果垫子非常脏味道非常大,可以用中性清洁液直接用水清洗,不建议用洗衣粉水来进行清洗。因为很难洗掉洗衣粉残留,会让爬行垫变滑。用布蘸中性清洁液水轻轻擦洗垫子,
3、再用清水冲干净,最后用干毛巾擦垫子,吸干多余水分并晾干即可。另外,不要让太阳直晒PVC垫子,会加速材质的老化。如果用洗衣粉清洗,洗衣粉愈少愈好,因为残留物会让爬行垫变滑。然后用湿布擦洗垫子,再冲干净。
八、爬爬垫该如何选择?
步骤/方式1
1、首选XPE、PVC材质爬行垫主要有4种材质,即EVA、EPE、XPE、PVC。推荐尽量选购XPE、PVC材质的爬行垫。
步骤/方式2
2、看检测报告
除了材质外,一定要看检测报告!
建议大家关注SGS认证(邻苯二甲酸酯检测) 和3C认证(重金属检测),两证齐全的爬行垫,入手更安心。
步骤/方式3
3、看类型
市面上的爬行垫一般分为整体式、折叠式、拼接式三种。整体式美观大方,容易打理,而拼接式可以给大家更多、更灵活的使用方式。折叠式介于两者之间。质监部门历年抽检中,拼接式爬行垫都是甲酰胺重灾区。
各位宝妈在买了爬爬垫后可以用除醛喷雾先处理一下再给宝宝用。
九、python 爬取新笔趣阁小说有哪些推荐?
嗨嗨,我是小圆。
相信大家都会看小说,但是有些小说看几章就要付费,奈何自己又没有会员,只能用用python爬取一下了。
基本开发环境
Python 3.6Pycharm
相关模块的使用
requestsparsel
安装Python并添加到环境变量,pip安装需要的相关模块即可。
单章爬取
一、明确需求爬取小说内容保存到本地
- 小说名字
- 小说章节名字
- 小说内容
# 第一章小说url地址
url = 'http://www.biquges.com/52_52642/25585323.html'url = 'http://www.biquges.com/52_52642/25585323.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
请求网页返回的数据中出现了乱码,这就需要我们转码了。
加一行代码自动转码。
response.encoding = response.apparent_encoding解析数据
根据css选择器可以直接提取小说标题以及小说内容。
def get_one_novel(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
print(title, content_str)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/25585323.html'
get_one_novel(url)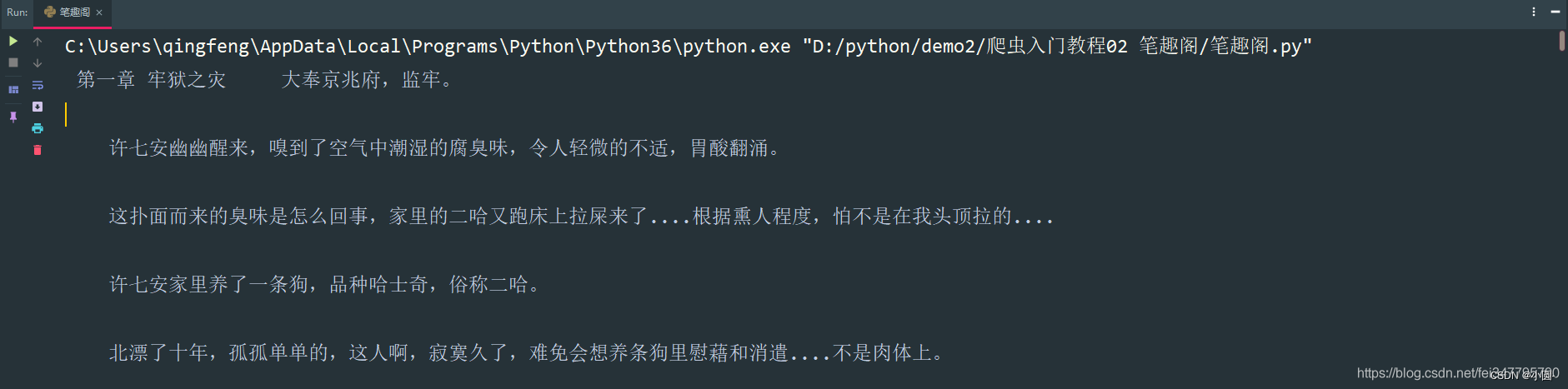保存数据(数据持久化)
使用常用的保存方式: with open
def save(title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
# 路径
filename = f'{title}\\'
# os 内置模块,自动创建文件夹
if os.makedirs(filename):
os.mkdir()
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename + title + '.txt', mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)保存一章小说,就这样写完了,如果想要保存整本小说呢?
整本小说爬虫
既然爬取单章小说知道怎么爬取了,那么只需要获取小说所有单章小说的url地址,就可以爬取全部小说内容了。
所有的单章的url地址都在 dd 标签当中,但是这个url地址是不完整的,所以爬取下来的时候,要拼接url地址。
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
for dd in dds:
novel_url = 'http://www.biquges.com' + dd
print(novel_url)
if __name__ == '__main__':
url = 'http://www.biquges.com/52_52642/index.html'
get_all_url(url)这样就获取了所有的小说章节url地址了。
爬取全本完整代码
import requests
import parsel
from tqdm import tqdm
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
response.encoding = response.apparent_encoding
return response
def save(novel_name, title, content):
"""
保存小说
:param title: 小说章节标题
:param content: 小说内容
:return:
"""
filename = f'{novel_name}' + '.txt'
# 一定要记得加后缀 .txt mode 保存方式 a 是追加保存 encoding 保存编码
with open(filename, mode='a', encoding='utf-8') as f:
# 写入标题
f.write(title)
# 换行
f.write('\n')
# 写入小说内容
f.write(content)
def get_one_novel(name, novel_url):
# 调用请求网页数据函数
response = get_response(novel_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 获取小说标题
title = selector.css('.bookname h1::text').get()
# 获取小说内容 返回的是list
content_list = selector.css('#content::text').getall()
# ''.join(列表) 把列表转换成字符串
content_str = ''.join(content_list)
save(name, title, content_str)
def get_all_url(html_url):
# 调用请求网页数据函数
response = get_response(html_url)
# 转行成selector解析对象
selector = parsel.Selector(response.text)
# 所有的url地址都在 a 标签里面的 href 属性中
dds = selector.css('#list dd a::attr(href)').getall()
# 小说名字
novel_name = selector.css('#info h1::text').get()
for dd in tqdm(dds):
novel_url = 'http://www.biquges.com' + dd
get_one_novel(novel_name, novel_url)
if __name__ == '__main__':
novel_id = input('输入书名ID:')
url = f'http://www.biquges.com/{novel_id}/index.html'
get_all_url(url)好了,分享到这里就结束了,感兴趣的朋友赶紧去试试吧!
喜欢的话记得给我一个关注和点赞哦
十、如何爬南岳?
衡山是中国南方的山岳风景区之一,被誉为“南岳”。登上衡山山顶,可以俯瞰群山如海,云海变幻,令人感受到大自然的神秘和壮美。但是,想要快速到达山顶,需要选择路线,下面就为大家介绍爬衡山路线攻略。
一、选择登山路线
衡山有四个登山口,分别是南岳大门、芙蓉峰、水帘洞和紫霄峰。其中,南岳大门和芙蓉峰是主要的登山口,而南岳大门是为热门的登山口。如果想要快速到达山顶,建议选择南岳大门登山口,因为这里的路线短。从南岳大门到南岳寺山顶,全长约11公里,需要步行4-5个小时。
二、制定合理的行程计划
登山时需要注意身体状况和天气情况,选择适当的时间和行程计划。衡山夏季气温较高,建议选择清晨或傍晚登山,避免中午时分的高温。同时,也需要根据自己的身体状况制定合理的行程计划,避免过度劳累。
三、准备必备装备
登山需要准备一些必备装备,如合适的鞋子、雨衣、手套、帽子、太阳镜、水壶等。在登山过程中,要注意保护自己的身体,避免受伤或感冒。
四、注意安全事项
登山时要注意安全事项,遵守登山规定,不要离开指定路线。在攀爬陡峭山路时,要保持冷静,小心谨慎,避免发生意外。同时,要注意环保,不乱扔垃圾,保持山区的干净整洁。
总之,爬衡山路线攻略是选择南岳大门登山口,制定合理的行程计划,准备必备装备,注意安全事项。只有做好这些,才能快速到达山顶,欣赏到衡山的壮美景色。
热点信息
-
在Python中,要查看函数的用法,可以使用以下方法: 1. 使用内置函数help():在Python交互式环境中,可以直接输入help(函数名)来获取函数的帮助文档。例如,...
-
一、java 连接数据库 在当今信息时代,Java 是一种广泛应用的编程语言,尤其在与数据库进行交互的过程中发挥着重要作用。无论是在企业级应用开发还是...
-
一、idea连接mysql数据库 php connect_error) { die("连接失败: " . $conn->connect_error);}echo "成功连接到MySQL数据库!";// 关闭连接$conn->close();?> 二、idea连接mysql数据库连...
-
要在Python中安装modbus-tk库,您可以按照以下步骤进行操作: 1. 确保您已经安装了Python解释器。您可以从Python官方网站(https://www.python.org)下载和安装最新版本...